
What is a Language Model?
Imagine a tool so powerful that it can predict and generate text that’s almost indistinguishable from what a human might write. This is the magic of a language model. These models, trained on vast amounts of text, learn patterns and use this knowledge to produce coherent and contextually relevant text sequences. But how do they do it? The secret lies in breaking down text into smaller units called tokens.
Tokenization: The Key to Understanding
Tokenization is the process of converting a sequence of characters (text) into a sequence of tokens. Each token represents a meaningful unit of text, which could be a word, a subword, or even a single character, depending on the model’s design. Let’s unlock this process with an example.
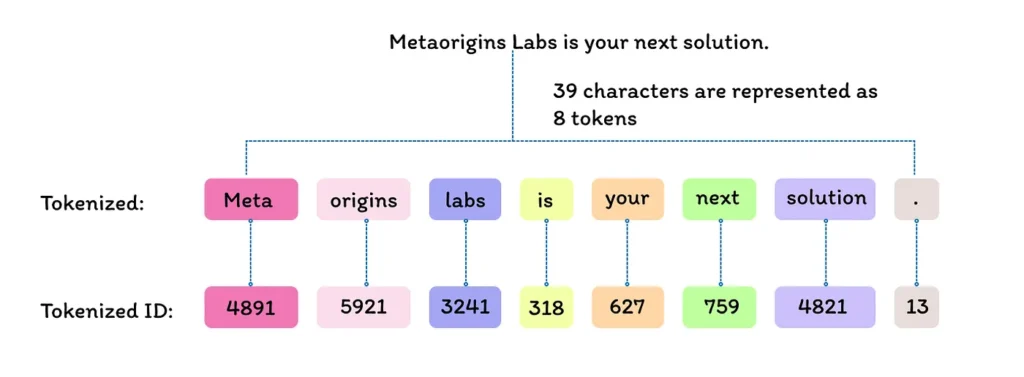
Text Input: Imagine the text “Metaorigins Labs is your next solution.”
Example :
Tokenization: The text is split into tokens. In this case, the sentence “Metaorigins Labs is your next solution.” is tokenized into the following tokens:
- “Meta”
- “origins”
- “Labs”
- “is”
- “your”
- “next”
- “solution”
Tokenized IDs: Each token is then mapped to a unique ID from the model’s vocabulary. For instance, the tokens in the example are assigned the following IDs:
- “Meta” -> 4891
- “origins” -> 5921
- “Labs” -> 3421
- “is” -> 318
- “your” -> 627
- “next” -> 759
- “solution” -> 4821
- “.” -> 13
The Art of Prediction
By predicting the next token, we can generate an entire sequence. The process involves:
- Given a context, selecting the next token.
- Adding that token to the context.
- Repeating this process iteratively.
For example, starting with: “Metaorigins Labs is your next solution for innovative AI-driven projects,” the model can generate text that flows seamlessly based on learned probabilities.
The Versatility of Text Completion
This ability to predict and complete text is incredibly versatile, enabling applications such as:
- “Question: What is the largest city in the world? Answer: Tokyo.”
- “Human: How are you? Chatbot: I am well, thanks.”
The Simplicity and Complexity of n-grams
Language models are built by training on extensive text corpora. The task involves predicting the next word given the context. A simple approach to this is the bigram model, which only uses the previous word as context. For example, the bigram model records the frequency of each word given the previous word. This concept can be generalized to n-gram models, where word frequencies are recorded for each group of n-1 previous words.
The Challenge of Long Contexts
Suppose our vocabulary consists of V tokens. When building an n-gram model, we must specify probabilities for all possible next tokens (V-1 values) for each group of n-1 context tokens. This can become computationally intensive as n increases.
The Importance of Context
Consider the following text: “My dog is named Joey. Yesterday Joey and I went for a long walk by the river. The spring weather was beautiful, and many people were out enjoying the day. Joey was happy too. I know this because he told me so.”
In this example, the fact that Joey is a dog is crucial information but lies outside the immediate context used in simple models. Hence, models must handle long contexts to maintain coherence and relevance over extended sequences of text.
The Significance of Tokenization
Tokenization is crucial for several reasons:
- Efficiency: It enables the model to process text more efficiently by breaking it down into manageable pieces.
- Vocabulary Management: Assigning unique IDs to tokens allows the model to manage a fixed vocabulary, simplifying the computational process.
- Context Understanding: Tokens help the model understand and generate text based on the context provided by the sequence of tokens.
Conclusion
Tokenization is a key step in the functioning of language models. By converting text into tokens and assigning unique IDs, models like GPT-4 can efficiently generate text that is both coherent and contextually appropriate. Understanding this process helps us appreciate the complexity and sophistication of modern language models.
So, the next time you hear about tokens in GenAI, you’ll know that they are the unsung heroes behind the scenes, making everything possible.
By Nitin Jain


